|
|

|
|
|
|
||
|
|
|
|
|
На этой странице — конспект беседы ЯНЗ (Якова Наумовича Зайдельмана) с Куками по теме: Какие бывают кодировкиЯНЗ. Давайте поговорим о кодировке символов. Вася, тебе знаком этот термин? Вася. Приблизительно. Это как-то связано с символами, которыми записано письмо. В наших почтовых программах The Bat! и Outlook Express есть такой пункт, он позволяет выбрать нужную кодировку из списка. Иногда это помогает прочитать письмо, которое сначала выглядит совершенно непонятно. Но точного смысла термина я не знаю. Петя. Кроме того, в The Bat! есть возможность работы с таблицами перекодировок. Вася. Да, я видел, но не разобрался в них. ЯНЗ. Что ж, ситуация довольно типичная. Многие пользователи электронной почты слышали слово “кодировка”, знают соответствующий пункт в меню своего мейлера, умеют применить его в некоторых простейших случаях, но не понимают реального содержания, которое стоит за этим понятием. Сегодня мы разберёмся в теоретической сущности кодировки (точнее, кодировок, так как проблемы обычно возникают именно из-за существования множества различных кодировок), а затем перейдём к практическим вопросам: как писать письма, чтобы у получателя не было лишних сложностей с чтением, и как прочитать полученное письмо с неправильной кодировкой. Вася. А нельзя ли сразу перейти к практике? ЯНЗ. А стоит ли? Можно, конечно, запомнить конкретные рецепты, которые обеспечат нормальную кодировку в большинстве случаев, но в сложной ситуации без понимания сути не обойтись. Петя. А мне, наоборот, интересно послушать суть дела. ЯНЗ. Вы, вероятно, знаете, что вся информация представлена в современных компьютерах в двоичном коде. Минимальная единица информации — 1 бит. Бит можно представить себе в виде переключателя, который может принимать одно из двух состояний: включён или выключен. Эти два состояния обычно обозначают единицей и нулём. Если взять несколько битов и последовательно записать состояние каждого из них, получится цепочка нулей и единиц. Эта цепочка и называется двоичным кодом. Можно договориться и сопоставить определённым последовательностям битов символы произвольного алфавита, например, буквы. Тогда с помощью двоичного кода можно представить любой текст, использующий выбранный алфавит. Вася. Получается, что единица и ноль в двоичном коде — не числа, а просто условные обозначения? И можно заменить их какими-то другими? ЯНЗ. Именно так. Более того, авторы некоторых книг по информатике специально вводят другие обозначения, чтобы не путать биты с цифрами и числами 0 и 1. Вася. Тогда азбуку Морзе можно считать двоичным кодом, в котором вместо нуля и единицы состояния битов обозначаются точкой и тире. Петя. Этот код является троичным, в азбуке Морзе используются три сигнала: точка, тире и пауза. ЯНЗ. Петя прав! Например, известный всем сигнал бедствия (СОС) записывается так:
Если убрать пробелы между буквами, то получится такая последовательность:
Эта последовательность не имеет однозначной расшифровки, так как в ней не заданы границы букв. Расставляя их в произвольных местах, мы можем вместо СОС получить ЖГИ, ИВНИ, ЕУМИЕ и многие другие сочетания. Петя. Так получается потому, что в азбуке Морзе разные символы обозначаются разным количеством знаков (точек и тире), поэтому нужен третий знак — пробел (пауза), чтобы расшифровка была однозначной. Если бы код каждого символа имел одинаковую длину, однозначная расшифровка была бы гарантирована. Вася. Зачем же в азбуке Морзе коды символов имеют разные длины? Петя. Это понятно: символы, которые в текстах встречаются чаще, имеют коды небольшой длины — набор и передача текста ускоряются, трафик получается менее объёмным. Например, популярная буква “Е” кодируется одной точкой, а редкая “Ш” — четырьмя тире. ЯНЗ. В теории кодирования рассматриваются коды переменной длины, гарантирующие однозначную расшифровку, и формулируются требования к таким кодам, но азбука Морзе этим требованиям не удовлетворяет. А коды переменной длины, действительно, позволяют записать текст более коротко. На этом их свойстве основаны все программы сжатия информация, в том числе популярные архиваторы. Но коды постоянной длины намного удобнее в использовании, поэтому они применяются значительно чаще. Вася. Мне кажется, мы слишком далеко отошли от главной темы. Давайте вернёмся к кодировкам. ЯНЗ. А мы как раз к ним и подбираемся. Давайте повторим основные положения, которые мы уже сформулировали:
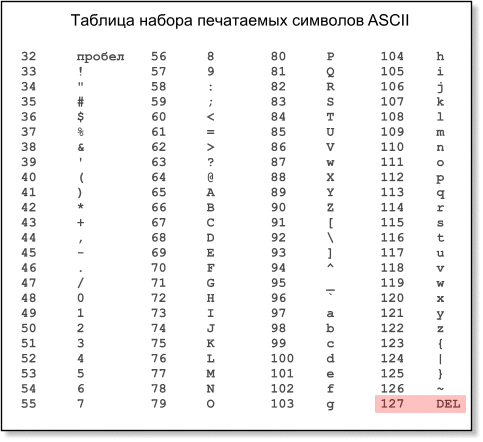
Петя. Всё понятно. Осталось только решить, сколько битов брать для каждого символа, и договориться о соответствии символов и кодов. ЯНЗ. Именно так. В результате получится таблица соответствия двоичных кодов и символов. Она называется кодовая таблица или просто кодировка. Вася. Значит, кодировка — это просто таблица? ЯНЗ. Да. И что особенно важно, эта таблица возникает не по законам природы, а как результат договорённости между людьми. Вася. Я понял! Таких договорённостей может быть много, поэтому и кодировок существует множество. Петя. Понятно, как возникают почтовые проблемы с кодировками. По сети передаются не символы, а двоичные коды. Если отправитель и получатель используют разные кодовые таблицы, расшифрованный текст не будет совпадать с исходным. ЯНЗ. Вы оба совершенно правы. Теперь давайте обсудим некоторые реально существующие кодировки. Петя. Наверное, построение любой кодировки начинается с определения количества битов для одного символа. Вася. Думаю, надо брать как можно меньше битов, чтобы сократить объём сообщения при передаче. ЯНЗ. Экономить, конечно, нужно, но не за счёт содержания. Количество битов должно быть достаточно для кодирования всех необходимых символов. Смотрите: один бит позволяет закодировать всего 2 комбинации: 0 и 1. Два бита дают 4 комбинации: 00, 01, 10, 11. Три бита обеспечивают 8 комбинаций и т. д. В общем случае, если для кодирования одного символа использовать N битов, можно закодировать 2N символов. Вася. В русском алфавите 33 буквы. Если отказаться от какой-нибудь редкой буквы, например Ё или Ъ, то хватит 5 бит: 25 = 32. ЯНЗ. Такое кодирование использовалось раньше для передачи телеграфных сообщений. Вы когда-нибудь видели старые телеграммы? Все буквы там только заглавные, а вместо знаков препинания используются специальные сокращения: ТЧК, ЗПТ, ВСКЛ. Петя. Получается, что надо отдельно кодировать заглавные и строчные буквы! Вася. И ещё знаки препинания! Но ведь мы говорили о символах алфавита? ЯНЗ. В информатике термин алфавит понимают не совсем так, как в естественных языках. В обычный алфавит входят только буквы. Например, в русском алфавите 33 буквы, в английском — 26. А в информатике принято учитывать и включать в алфавит все символы, которые встречаются в тексте: не только буквы, но и знаки препинания. Пробел, отделяющий слова друг от друга, тоже считается отдельным символом. Вася. Я хочу сам подсчитать, сколько же нужно битов для одного символа. Нам нужно закодировать 2 раза по 33 буквы (заглавные и строчные), 10 цифр — это уже 76 символов. Теперь знаки препинания: точка, запятая, восклицательный и вопросительный знаки, двоеточие, точка с запятой… Петя. Скобки, кавычки, тире… Вася. Да, все знаки сразу вспомнить трудно. Будем считать, что их примерно два десятка. Всего получается порядка 100 символов. Получается, что шести битов явно недостаточно (26 = 64), а семи должно хватить (27 = 128). ЯНЗ. Примерно так же рассуждали разработчики американского стандарта в начале 1960-х годов. Они решили, что для записи текстов на английском языке вполне достаточно 7-битного кодирования. Вася. А разве в это время уже была электронная почта? ЯНЗ. Почты в современном смысле ещё не было, но ведь кодировки нужны не только для пересылки. Любой текст, который хранится или обрабатывается на компьютере, должен быть представлен в виде двоичного кода, а для этого нужны кодовые таблицы. На заре компьютеризации, в 1940–1950-х гг. чуть ли не каждая модель компьютера имела собственную кодировку. Проблем из-за этого почти не возникало, так как обмен информацией между компьютерами был событием редким, а если данные записываются и читаются на одной машине, то почти всё равно, как они кодируются. Затем ситуация изменилась. Машин стало много, появились первые сети, возникла проблема компьютерного взаимопонимания. Для её решения американцы в начале 60-х годов разработали новую кодировку. После нескольких незначительных модификаций (менялся набор знаков пунктуации и коды некоторых из них) к концу 60-х годов эта кодировка стала в США почти общепринятой. Она была утверждена ANSI (American National Standard Institute — американский национальный институт стандартов) и получила название ASCII (American Standard Code for Information Interchange — американский стандартный код обмена информацией). Вася. Какие же символы вошли в ASCII? ЯНЗ. ASCII — 7 битная кодировка, она включает 128 символов. Код каждого символа — двоичное число от 0 до 127. Первые (от 0 до 31) и последний (127) коды представляют управляющие символы. Они не имеют графического изображения (поэтому иногда их называют “непечатными” или “непечатаемыми”) и используются для представления и передачи дополнительной информации о структуре текста. Среди них есть, например, символы перехода на новую строку (десятичный код 10), табуляции (десятичный код 9), удаления (десятичный код 127) и другие.
Символы с кодами от 32 до 126 — печатные (или печатаемые). Им соответствуют латинские буквы, цифры и знаки. Набор знаков ASCII включает все основные знаки препинания и простейшие математические знаки. Цифры от 0 до 9 расположены подряд (коды от 48 до 57), заглавные и строчные буквы тоже расположены подряд, причем в алфавитном порядке.
Коды заглавных букв — от 65 до 90, строчных — от 97 до 122. Разница между заглавной и соответствующей ей строчной буквой всегда составляет ровно 32. В двоичном представлении это означает, что они отличаются ровно одним битом. Такие свойства ASCII очень упрощают программирование многих типовых операций (например, нахождение в тексте букв и цифр или замену прописных букв на строчные). Возможно, именно это обеспечило всеобщее признание ASCII. Петя. ASCII сразу стала единственной кодировкой для английского языка? ЯНЗ. На самом деле даже сегодня ASCII нельзя считать единственной кодировкой для английского языка. Например, фирма IBM, компьютеры которой господствовали на мировом рынке в 1970-е годы, очень долго придерживалась кодировки EBCDIC (Extended Binary Coded Decimal Information Code — расширенный двоично кодированный десятичный информационный код). Эта кодировка происходит от кодов для перфокарт, которые использовались еще в конце XIX века, задолго до появления первых компьютеров. В машинах IBM использовались практически те же перфокарты, и кодировка EBCDIC разрабатывалась таким образом, чтобы облегчить аппаратное преобразование перфокарточных кодов (программное преобразование тогда считалось неоправданной роскошью — машинное время было очень дорого). Отсюда некоторые кажущиеся странности этой кодировки: она 8 битная, но очень многие комбинации не используются, даже буквы расположены не подряд, а разбиты на несколько групп, между которыми расположены “мёртвые зоны” неиспользуемых кодов. EBCDIC в несколько изменённом виде (изменения в основном сводятся к тому, что кодировка пополняется новыми символами, которые занимают многочисленные пустующие места) до сих пор используется на больших компьютерах IBM. Однако, персональный компьютер IBM PC, выпущенный в 1981 году, использовал кодировку ASCII. С 1980-х годов кодировка ASCII стала мировым стандартом. Отдельные системы использовали другие кодировки в качестве внутренних, но практически весь информационный обмен осуществлялся в ASCII. Стандарт RFC 822 объявил ASCII стандартной кодировкой электронной почты. Петя. Понятно, почему этот стандарт оказался недостаточным для неанглийских текстов. В 7 битной кодировке просто не нашлось места для символов из неанглийских алфавитов. Вася. А мне непонятно. Почти все западноевропейские языки, включая английский, используют один и тот же латинский алфавит. Почему кодировку, в которой есть буквы этого алфавита, можно использовать для английского языка и нельзя для французского, немецкого, шведского? ЯНЗ. Хороший вопрос. Дело в том, что английский оказался единственным языком, использующим “чистый” латинский алфавит. Во всех остальных языках есть так называемые диакритические знаки, то есть надстрочные и подстрочные дополнения к основным буквам. Например, во французском языке существует целых 5 способов записать букву E. Стандартная ASCII не содержит кодов для всех этих символов, поэтому она оказалась недостаточной для французского и других западноевропейских языков. Вася. Странно как-то. В конце концов, писали бы просто E, и по смыслу догадывались, как в каждом конкретном случае читать эту букву. У нас ведь точки над Ё почти никогда не ставятся, и никому это не мешает. ЯНЗ. Утверждение о том, что это никому не мешает, весьма спорное. Я мог бы привести много примеров, в которых отсутствие точек над Ё ведёт к путанице, но по сути сказано верно: в современном русском языке буква Ё на печати действительно почти никогда не обозначается. Но ведь в русском языке не одна, а две диакритические буквы. Кроме Ё, есть ещё Й. Представьте себе, что вместо Й в текстах везде стоит И. Можете даже провести эксперимент: возьмите любой компьютерный документ с текстом на русском языке, замените все Й на И, прочитайте полученное и поделитесь впечатлениями. Вася. Думаю, читать будет очень непривычно и неудобно. ЯНЗ. И это из-за одной буквы! Стоит ли после этого удивляться, что французам, у которых диакритических знаков значительно больше, не захотелось обходиться без них? К счастью, у данной проблемы нашлось простое естественное решение. Компьютерная память состоит не из отдельных битов, а из групп по 8 бит, которые называются байтами. При компьютерном хранении текстов в каждом байте обычно хранится 1 символ. Если использовать “чистую” ASCII, то 1 бит в каждом байте пропадает. Но если сделать этот бит значащим, то вместо 128 символов можно закодировать 256. Вася. Больше 100 дополнительных символов! Этого, наверное, хватит для всех диакритических знаков! ЯНЗ. ЯНЗ. Как ни странно, для всех диакритических знаков из всех использующих латинский алфавит языков даже этого недостаточно. Но все необходимые знаки для одного произвольного языка вполне возможно закодировать с помощью 8 бит. Обычно символы с кодами от 0 до 127 те же, что в стандартной ASCII, а от 128 до 255 размещаются дополнительные символы. Кодировки, построенные по такому принципу, называются расширенными вариантами ASCII. Вася. Наверное, для расширенных ASCII тоже нужны стандарты. Ведь если каждый будет кодировать дополнительные символы по своему вкусу, опять начнётся несовместимость и неразбериха. ЯНЗ. Разумеется. Такие стандарты стали появляться в начале 1980-х годов. Широко применялись, например, кодировки, включённые в популярную операционную систему MS DOS. В этой системе кодировки назывались кодовыми страницами — Code Page (CP) и обозначались трёхзначными номерами. Самой популярной в западных странах была кодовая страница 437, включавшая дополнительные буквы французского, немецкого и испанского языков, отдельные греческие (в основном, те, которые часто используются в математических текстах), многочисленные символы псевдографики для рисования одинарных и двойных линий, несколько математических символов. Чуть позже появилась страница 850, в которой за счёт некоторого сокращения псевдографики было увеличено количество букв для западноевропейских языков. Вася. А что обозначают номера кодовых страниц? ЯНЗ. Честно говоря, не знаю. Видимо, это один из тщательно охраняемых секретов фирмы Microsoft. Вполне вероятно, что для их определения использовался датчик случайных чисел. В общем, к середине 1980-х годов существовало уже сравнительно много вариантов расширенной ASCII, часто включавших одни те же символы, но с разными кодами. Чтобы как-то упорядочить это буйное разнообразие, международная организация стандартизации (ISO) в 1987 году приняла стандарт под номером 8859. Этот стандарт закрепил несколько вариантов расширенной ASCII, которые получили названия ISO-8859-1 (используется для французского, испанского, португальского, немецкого, скандинавских и других западноевропейских языков), ISO-8859-2 (чешский, польский, венгерский и другие восточноевропейские языки) и т. д. Семейство ISO-8859 продолжает развиваться и пополняться новыми кодировками. Последние две кодировки — ISO-8859-15 и ISO-8859-16 — опубликованы соответственно в 1999 и 2001 году. Их главное отличие от кодировок предыдущего поколения — наличие специального символа для знака новой европейской валюты евро. Петя. Мы так долго обсуждаем проблемы кодирования западноевропейких алфавитов! Но мне, например, значительно чаще приходится писать на русском языке, чем на немецком или испанском. Вася. Наверное, для русского языка тоже существуют свои кодовые страницы. ЯНЗ. Да, и к сожалению, не одна. Если хотите, я сделаю краткий исторический обзор основных кодировок русского алфавита, которые применяются сейчас и применялись в недавнем прошлом. Петя. Да, это было бы очень интересно. ЯНЗ. Вася, а ты не возражаешь? Вася. А что делать? Придётся терпеть и слушать! ЯНЗ. Чтобы не слишком изнурять Васю, не будем заглядывать в историю слишком глубоко и говорить о представлении русских текстов в компьютерах 1940-60-х годов. Пожалуй, этот пласт истории лежит слишком уж далеко от нашей основной темы. В 1970-е годы основу советского компьютерного парка составляли машины единой серии — ЕС ЭВМ (Между прочим, слово “компьютер” считалось тогда жаргонным и его использование не поощрялось. Даже в переводных изданиях английское слово computer обычно переводилось как ЭВМ.) Архитектурно и программно ЕС ЭВМ были совместимы с популярными в то время машинами IBM360 и IBM370, на которых использовалась кодировка EBCDIC. Для ЕС ЭВМ была разработана кодировка ДКОИ (Двоичный Код Обмена Информацией). Латинские буквы (буквы использовались только заглавные), цифры, знаки пунктуации имели в ДКОИ те же коды, что и в EBCDIC, а для русских букв были задействованы дополнительные коды, которые в оригинальной EBCDIC не использовались. При этом кодировались только те русские буквы, которые по начертанию не совпадали с латинскими. Например, для букв Б, Г, Д вводились дополнительные коды, а вместо А, В, Н использовались совпадающие по начертании латинские буквы. Вася. Но это же очень неудобно! ЯНЗ. Человеку, читающему напечатанный текст, это практически всё равно. Неудобства возникают при программной обработке текстов, но такие задачи были в то время сравнительно редкими. Да и понятие удобства весьма относительно: хорошо помню, как я когда-то после долгой работы считал странным и неудобным наличие в других системах двух разных кодов для внешне неотличимых русской и латинской букв А. В начале 1980-х годов ЕС ЭВМ стали постепенно терять своё господствующее положение. Началось распространение так называемых малых машин. Вася. Персональных? ЯНЗ. Нет, до персональных компьютеров в современно понимании было ещё далеко. Малыми тогда назывались, например, машины серии СМ ЭВМ, хотя сегодня термин “малые” по отношению к ним может вызвать только улыбку. Но мы отвлеклись. История вычислительной техники — отдельная неисчерпаемая тема, но сегодня нас интересуют кодировки. Прообразом машин серии СМ были компьютеры PDP-11 фирмы DEC (Digital Equipment Corporation). В PDP-11 аппаратно и программно использовалась ASCII, причём не расширенная, а базовая, 7-битная. Для СМ ЭВМ была создана кодировка, которая получила название КОИ-7 (Код Обмена Информацией 7-битный). КОИ-7 почти во всём совпадала с ASCII, но вместо строчных латинских букв в неё были включены заглавные русские. Петя. Но ведь русских букв больше! Их 33, а латинских всего 26. ЯНЗ. Именно поэтому из русского алфавита в КОИ-7 выпали Ё и Ъ. Кроме того, пришлось пожертвовать некоторыми символами ASCII: в КОИ-7 не было фигурных скобок и некоторых других русских знаков, их место заняли русские буквы. Петя. А как расположены русские буквы в КОИ-7? По алфавиту? ЯНЗ. Нет. Каждая русская буква заняла место “соответствующей” латинской. Начало русского алфавита в КОИ-7 оказалось таким: ЮАБЦДЕФ… Вася. Но это же неудобно! ЯНЗ. Для чтения и письма алфавитный порядок не имеет никакого значения. Проблемы возникают только при сортировке. Действительно, для алфавитного упорядочения русских списков в КОИ-7 приходилось принимать специальные меры, использование стандартных процедур приводило к несколько непривычным результатам. Но было в такой схеме размещения русских букв одно важное достоинство. Сегодня оно может показаться странным и вызвать сочувственную улыбку, а тогда воспринималось как нечто вполне естественное. На машинах серии СМ часто применялись программы с английским интерфейсом, написанные для оригинальных PDP-11. Нередко приходилось читать и документацию на английском языке. Разумеется, и тексты, и сообщения программ были написаны на нормальном английском языке, с использованием строчных букв. На отечественных машинах вместо них появлялись заглавные русские буквы. Английский текст получался изуродованным, но вполне распознаваемым — именно потому, что русские буквы располагались не по алфавиту, а по соответствию с латинскими. При некотором навыке сообщение DЕЖИЦЕ НОТ РЕАДЫ легко читалось как Device not ready. Петя. А что, нельзя было шрифт поменять? ЯНЗ. Нельзя. В дисплеях и печатных устройствах того времени шрифт был ровно один, и задавался он аппаратно, без участия программных средств. Петя. Да, интересное было время. ЯНЗ. Оно оказалось не слишком долгим. В середине 1980-х появились дисплеи с полным набором символов, включавшим заглавные и строчные русские и латинские буквы. Примерно в это же время разрабатывались первые отечественные адаптации операционной системы UNIX. Там была использована полная кодировка, естественно, 8-битная. Она была построена на основе КОИ-7 и получила название КОИ-8. Петя. Это та самая КОИ-8, которая сейчас используется в электронной почте? ЯНЗ. Практически да. За прошедшее с тех пор время были незначительные изменения, но все русские буквы (кроме Ё, которой в первоначальном варианте вообще не было) остались на своих местах. Но давайте не будем торопиться, разговор о современном положении дел ждёт нас впереди. КОИ-8 построена по правилам расширенной ASCII: первая половина кодовой таблицы (от 0 до 127) совпадает с ASCII, вторая половина содержит дополнительные символы. Коды заглавных русских букв в КОИ-8 отличаются от КОИ-7 только одним битом — самым старшим, которого в 7-битной кодировке вообще нет, а во второй половине 8-битной он равен 1. Поскольку в первой половине таблицы своё законное место заняли строчные латинские буквы, заглавные русские буквы стали на 1 бит отличаться от соответствующих латинских, но строчных. А строчные русские буквы разместили так, чтобы они на 1 бит отличались от заглавных латинских. Петя. В таком сходстве кодов есть какой-то смысл или это просто забавный казус? ЯНЗ. Смысл есть. Помните, я рассказывал, как соответствие кодов русских и латинских букв в КОИ-7 позволяло читать английские сообщения, которые оказывались записаны русскими буквами? Соответствие кодов в КОИ-8 позволило решить обратную проблему. Некоторые программы и аппаратные устройства, рассчитанные на 7-битную кодировку, не обращают внимания на восьмой бит и заменяют символы второй половины 8-битной кодовой таблицы на символы первой половины. При таком искажении русские буквы КОИ-8 превращаются в соответствующие латинские. Полученный при этом rUSSKIJ TEKST выглядит, конечно, уродливо, но его всё же можно прочитать. Вася. Выглядит и в самом деле уродливо. Мало того, что вместо русских букв латинские, так ещё и большие буквы с маленькими перепутаны. А нельзя было сделать такую кодировку, чтобы при исключении восьмого бита заглавные и строчные буквы не менялись местами? ЯНЗ. Наверное, можно, и это действительно было бы удобнее. Но КОИ-8 получилась именно такой из-за особенностей существовавшей тогда аппаратуры и необходимости работать с КОИ-7 и КОИ-8 на одних и тех же машинах. А внесение изменений сейчас может вызвать разве что новую путаницу. Увы, это далеко не единственный случай неудобств, с которыми приходится мириться из-за решений, принятых когда-то в прошлом. Впрочем, удобства и неудобства всегда относительны. Хорошо, конечно, иметь возможность прочитать текст с потерянными битами, но платить за это пришлось отказом от привычного алфавитного порядка. А в результате во многих программах неверно выполнялась сортировка. Во второй половине 1980-х в СССР стали появляться компьютеры, совместимые с IBM PC. Для них была разработана новая кодировка, в которой все русские буквы располагались строго по алфавиту. Эту кодировку даже утвердили в качестве государственного стандарта (ГОСТ). Обычно её так и называют — кодировка ГОСТ. В кодировке ГОСТ русские буквы заняли места, которые в CP437 (напомню, что в тот момент это была самая распространённая кодировка для оригинальных IBM PC) занимали символы псевдографики для рисования таблиц: одинарные и двойные линии и различные варианты их пересечений. Эта особенность оказалась роковой: во многих популярных программах того времени, в том числе в очень распространённой у нас Norton Commander использовалась табличная псевдографика. Если компьютер был настроен на кодировку ГОСТ, то все рамочки оказывались состоящими из русских букв, и выглядело это не очень привлекательно. В качестве альтернативы была предложена другая кодировка, которую так и назвали — альтернативная. В альтернативной кодировке все символы рисования таблиц имеют те же коды, что и в CP437. Русские буквы расположены по алфавиту, но не подряд: между строчными “п” и “р” размещаются 48 знаков псевдографики. Чуть позже в альтернативной кодировке были заменены некоторые редкие символы. Этот вариант получил название “альтернативная модифицированная кодировка” и в течение нескольких лет был фактическим стандартом для отечественных персональных компьютеров. Фирма Microsoft даже включила этот вариант в состав MS DOS под названием CP866. Петя. Альтернативная модифицированная… Ничего не скажешь, подходящее название для самой популярной кодировки. Похоже, такое название хорошо отражает суть общей ситуации с русскими кодировками. ЯНЗ. Ты прав, и дальнейшее развитие событий подтверждает это. В конце 1980-х годов ISO (международная организация стандартизация выпустила стандарт ISO8859-5 За основу был взят официально действовавший советский стандарт, то есть кодировка ГОСТ. Думаю, вы не удивитесь, когда узнаете, что этот стандарт фактически оказался мертворожденным и на практике применяется крайне редко. Петя. Редко или никогда? ЯНЗ. Редко. Некоторые программы используют в качестве стандартной русской кодировки именно ISO8859-5. Я подозреваю, что среди разработчиков этих продуктов почему-то не оказалось программистов из России, и некому было объяснить, что наша жизненная реальность довольно далека от международных стандартов. В начале 1990-х годов появилась русская версия Microsoft Windows. Хотя в Microsoft уже была одна русская кодировка (CP866, она же альтернативная модифицированная, включённая в DOS), применять её в Windows разработчики из Microsoft не стали. Они решили, что поскольку Windows — графическая система, символы псевдографики уже не нужны, и можно устранить разрыв в размещении русских букв, который так некрасиво смотрелся и создавал некоторые неудобства для программистов в CP866. Кодировка ГОСТ и её международный вариант ISO8859-5 им тоже чем-то не понравилась. В результате появилась совершенно новая кодировка русского алфавита. В Microsoft ей присвоили номер кодовой страницы 1251, и теперь эта кодировка обычно упоминается как CP1251, Windows-1251 или просто как русская кодировка Windows. А чтобы жизнь была совсем весёлой, во всех консольных (то есть работающих в текстовом, а не в графическом окне) приложениях Windows по-прежнему используется кодировка DOS — CP866. В Windows-1251 русские буквы (кроме Ё) расположены по алфавиту, их коды расположены подряд, без пропусков. Интересно отметить, что русские буквы в этой кодировке расположены на тех же местах, что и в КОИ-8, но в другом порядке. Для полноты картины осталось упомянуть кодировку Макинтош. Фирма Apple пришла на наш рынок и занялась русификацией своих машин сравнительно поздно, уже в 1990-х годах, к этому моменту уже существовали и соперничали КОИ-8, CP866, Windows-1251. Но программисты Apple решили не идти проторенным путём и создали свою кодировку. Заглавные русские буквы в ней совпадают с CP866, а строчные — с Wndows-1251. Исключением оказалась буква “я” — код 255 в ОС Макинтош не может использоваться как значащий символ. Ну и как обычно, буква Ё оказалась отделена от всего остального алфавита. Вася. Да уж… Такая пёстрая картина, что голова кружится. ЯНЗ. Хорошо тебя понимаю. Даже у специалистов такое разнообразие кодировок часто вызывает сложности. Петя. У меня возник вопрос. В компьютерных текстах на русском языке часто встречаются англоязычные слова и фрагменты. Например, тексты программ или заголовки в электронных письмах. ЯНЗ. Совершенно верно. Даже в нашем сегодняшнем диалоге встречались слова ASCII, ISO, Windows, Microsoft, Apple, которые естественно записывать по-английски. И в чём проблема? Петя. Никаких проблем нет, если все вставки — английские. Поскольку все современные русские кодировки построены как расширенные ASCII, они заведомо включают все буквы английского алфавита. А что делать, если в русский текст нужно включить фрагменты, например, на французском? Ведь в русских кодировках нет диакритических символов, а в западноевропейских — нет русских букв. Вася. Действительно… Получается, что Лев Толстой не смог бы написать “Войну и мир” на компьютере! ЯНЗ. Эта проблема действительно существует. 8-битой кодировки оказывается достаточно практически для любого языка с письменностью на алфавитной (не иероглифической) основе. Но если в тексте нужно сочетать символы двух и более языков, всё оказывается не так просто. Для языков на базе латинского алфавита эта проблема частично решена в наборе кодировок ISO. В 10 разных вариантах кодирования латинского алфавита многие диакритические символы повторяются в различных комбинациях, давая возможность выбрать подходящую кодировку для сочетания многих пар языков. Но если надо сочетать, например, русский с французским, подходящей 8-битной кодировки не существует, приходится, например, отказываться от диакритических символов, затрудняя нормальное восприятие французского текста. А для сочетания русского языка с греческим или ивритом нет даже такого урезанного варианта. Петя. Но в том же Word можно набирать текст на любых языках. Надо только каждый раз выбрать правильный шрифт. ЯНЗ. Да, это одно из решений проблемы. Но в этом случае нужно сохранить в файле не только коды символов, но и указания о том, где какой шрифт (а фактически язык) используется. Полученный таким образом документ уже нельзя считать простым закодированным текстом, он имеет более сложную информационную структуру. На универсальное решение всех проблем с кодировками претендует система кодирования Unicode, первая версия которой вышла в 1991 году. Первоначально Unicode задумывался как 16-битная кодировка. 16 битов позволяют закодировать 216 = 65536 символов, предполагалось, что этого хватит для всех мыслимых языков, включая языки с иероглифической письменностью. Вася. И что, не хватило? ЯНЗ. Не хватило. Поэтому современный Unicode представляет собой не обычную кодовую таблицу, а сложный набор правил и алгоритмов, позволяющих получить практически неограниченное количество различных символов. Unicode сегодня используется всё шире. В Unicode, например, хранятся все внутренние данные в последних версиях Microsoft Windows и Microsoft Office, в Unicode разрабатываются многие Интернет-сайты, особенно многоязычные. Петя. Если Unicode решает все проблемы, почему он до сих пор не вытеснил все 8-битные кодировки? ЯНЗ. Использование Unicode решает одни проблемы, но создаёт другие. Программы становятся более сложными, увеличиваются объёмы файлов, требуются специальные совместимые с Unicode шрифты. Так что 8-битные кодировки пока рано совсем сбрасывать со счетов. Для обычных текстов на одном языке они пока остаются наиболее удобным представлением.
|
|
|
|