|
|

|
|
|
|
||
|
|
Инструменты поиска в Интернете
ИндексыНа этой странице:
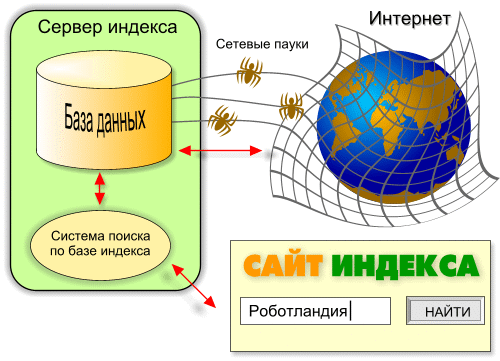
Каталоги и рейтинги удобны для поиска сайтов по теме, но они плохо помогают, когда нужно найти конкретную информацию, фрагмент текста, содержащий определённые ключевые слова. Кроме того, каталоги и рейтинги охватывают лишь очень небольшую часть Интернета, и даже в ней плохо отслеживают изменения, которые происходят в Интернете каждый день. Более мощным инструментом поиска с широким охватом Сети являются индексы (поисковые системы, поисковики) — сервера, которые автоматически, при помощи специальных программ (их называют пауками) постоянно сканируют страницы Интернета, и индексируют их, то есть заносят в свою огромную базу данных. Когда пользователь выдаёт запрос в индекс, поиск выполняется уже не в Интернете, а в базе данных индекса, и поэтому отнимает очень мало времени. На сервере индекса располагаются:
Сетевые пауки трудятся непрерывно и автономно: они обшаривают по гипертекстовым ссылкам все закоулки Паутины и заносят информацию в базу данных, периодически проводя ревизию уже проиндексированного материала. Популярные сайты с быстро обновляемым содержимым (новостные порталы, Интернет-магазины, аукционы и т. п.) переиндексируются несколько раз в час, обычные — несколько раз в месяц или реже. Стартовыми точками для пауков являются крупные популярные сайты. Паук начинает свой путь с такого сайта, обрабатывает его, и двигается дальше по внешним ссылкам сайта. Система поиска по базе индекса обслуживает запросы пользователей. Многие поисковые системы предоставляют возможность авторам самостоятельно добавлять свои ресурсы в очередь на индексирование. Это существенно ускоряет обработку сайта, а в случаях, когда никакие внешние ссылки не ведут на сайт, вообще оказывается единственной возможностью заявить о его существовании. Понятие индекса
В Интернете термин “индекс“ закрепился за поисковыми системами, принцип работы которых был описан выше. Но кроме собственно индекса, то есть словаря слов со ссылками, база данных поисковой системы содержит и сами Web-страницы в сжатом виде. Индекс поисковой системы, как и индекс обычной книги, существенно повышает скорость поиска: ведь объём индекса во много раз меньше самого проиндексированного материала, а кроме того, записи в индексе упорядочены по алфавиту.
В силу алфавитного упорядочивания индекс не нужно просматривать
подряд: начинаем с раздела на первую букву искомого слова, внутри
этого раздела переходим в подраздел со второй буквой и так
далее. То есть программное обеспечение может работать с индексом
примерно так, как человек работает с индексом книги.
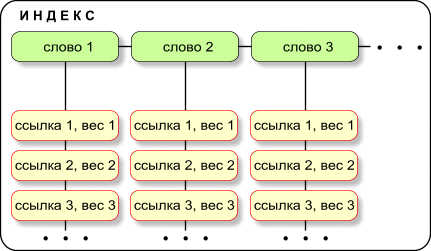
Вес ссылки на документ для слова из индексаВ индексе поисковой системы с каждым словом или фразой связан список ссылок на документы в которых это слово или фраза встречаются. Кроме того, каждая ссылка снабжается весом — числовой оценкой её значимости.
При вычислении веса ссылки учитывается индекс цитирования документа (ИЦ). Более весомым считается документ, на который есть много ссылок с других сайтов, причём цитирование с крупных популярных сайтов оценивается выше. Вес ссылки выше для более “свежих” страниц, то есть страниц с более новой датой обновления. Ссылка имеет повышенный вес, если слово входит в состав её URL (например, слово microsoft входит в состав ссылки на сайт компании: www.microsoft.com). Ссылка имеет повышенный вес, если слово входит в состав названия окна, в которое выводится страница документа. В HTML-коде название окна задаётся тегом TITLE: Пример (фрагмент HTML-кода):
<TITLE>Роботландский университет</TITLE> Вес ссылки повышается, если слово входит в состав списка ключевых слов страницы (тег META с атрибутом keywords) или в состав описания страницы (тег META с атрибутом description). Ключевые слова и описания задаются автором сайта и не отображаются на экране при показе страницы браузером. Пример (фрагмент HTML-кода):
<META name="keywords"
content="Роботландский Университет,
дистанционное обучение,
сетевые курсы, программы для школы,
программно-методическое обеспечение,
интерактивные учебники, информатика,
вебдизайн, веб-дизайн">
<META name="description"
content="Программно-методические продукты для школ.
Сетевое обучение учителей и школьников.
Интерактивные учебники.">
Ссылка имеет повышенный вес, если слово входит в состав альтернативного текста картинки (атрибут alt тега IMG). Пример (фрагмент HTML-кода вывода на экран картинки):
<IMG src=./pic/title.gif width=423 height=53 border=0
alt="Роботландия">
Кроме того, при подсчёте веса ссылки учитываются разные параметры появления слова в тексте документе:
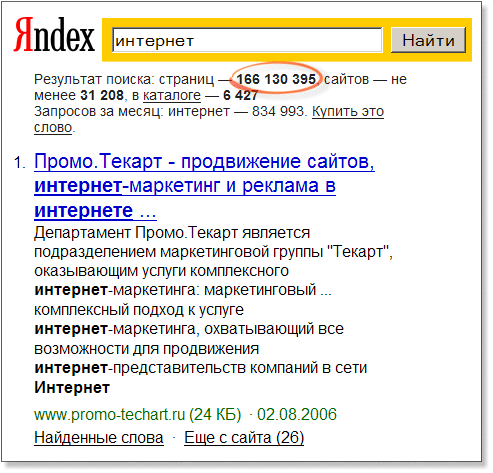
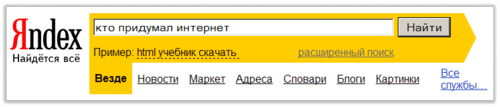
Выше перечислены далеко не все параметры, которые влияют на вес ссылки на документ, в котором упоминается слово из индекса поисковой системы. Кроме того, для вычисления числового значения веса (по всем перечисленным параметрам и тем, которые не упомянуты) разные поисковые системы используют разные алгоритмы (которые, как правило, держатся в секрете). Ранжирование результатов поискаВася задал в строке поиска Яндекса слово “интернет”. Результат его ошеломил: поисковая система через секунду сообщила, что нашла более 166 миллионов страниц с этим словом (расположенных более чем на 31 тысяче сайтов) и предъявила первые десять ссылок с фрагментами текста, содержащих искомое слово:
Вася уточнил запрос, задав фразу “поиск в интернете”. Результат — 3 с половиной миллиона страниц. Ещё одно уточнение: “список поисковых систем интернета”. Результат — 886 106 страниц. Если Вася, действительно, хотел найти список поисковиков Интернета, то задавать в качестве образца поиска только популярное слово “интернет” было изначально плохой идеей. Уточнение фразы поиска привело к уменьшению количества найденных страниц почти в 200 раз. Однако полный просмотр результатов по-прежнему остаётся нереальной задачей. Если бы индексы выдали результаты в том порядке, в котором находили бы страницы в своей базе данных, их услуги были бы никому не нужны. Проще было бы искать вручную, пользуясь коллекциями ссылок. Кроме того, есть каталоги и рейтинги, в которых поиск выполняется по хорошо организованной структуре, представленной в виде тематического дерева. Конечно, коллекции ссылок, каталоги и рейтинги, охватывают лишь небольшую часть Интернета и не самую “свежую”. Но поиск при помощи этих инструментов, по крайней мере, предсказуем и занимает мало времени. Однако индексы в Интернете пользуются большой популярностью и к ним обращаются гораздо чаще, чем к каталогам и рейтингам. Почему? Причина в том, что индекс ранжирует список результатов в порядке релевантности — степени соответствия полученных результатов ожидаемым. Первыми в списке оказываются те страницы, которые имеют большую релевантность. В силу этого достаточно просмотреть первые 10–20 страниц из сотен тысяч найденных, чтобы обнаружить подходящую. Если подходящая страница среди первых двадцати в списке не найдена, надо переформулировать запрос и повлиять на релевантность результата при помощи расширенного (сложного) поиска или языка запросов (о расширенном поиске и языке запросов рассказано в следующих разделах). Как поисковая система ранжирует результаты поиска по релевантности? При подсчёте релевантности учитывается вес ссылки для каждого слова из словаря индекса. Когда запрос представлен не одним словом, а фразой, в игру вступают дополнительные соображения. Так поисковиками особенно ценится точное вхождение искомой фразы в текст документа. Когда точного вхождения нет, оценивается близость расположения искомых слов в тексте и их порядок. Например, по запросу “выпросил фонарь” будут найдены и документы с фразами “фонарь в награду выпросил” и “выпросил в награду за свою долгую верную службу старый фонарь”, но их релевантность окажется ниже при прочих равных условиях. Релевантность документа повышается, если морфология запроса (форма используемых слов: падежи, единственное и множественное число и т.д.) совпадает с морфологией найденной фразы. Так при запросе “день идёт” будут найдены и документы с фразой “дни шли”, но их релевантность окажется ниже при прочих равных условиях. Следует отметить, что не все индексы настолько хорошо знают русский язык, чтобы выполнять поиск, используя разные формы ключевого слова (например, беги, бежал, бегут и т. п. вместо заданного “бежать”). Индексы Рунета, такие как Яндекс, Рамблер, Апорт — спецы в этом вопросе. Мировой гигант Yahoo морфологию русского языка совсем не знает. Очень хороший поисковик Google знаком с ней поверхностно. Несмотря на то, что стоп-слова (к которым относятся предлоги, союзы, частицы и междометия) при поиске в расчёт не берутся, при ранжировании документов они всё же учитываются. При прочих равных условиях совпадение стоп-слова повышает релевантность документа. Точные алгоритмы ранжирование результатов поиска держатся авторами индекса в секрете. Причина таинственности кроется, с одной стороны, в коммерческой конкуренции (ранжирование — основа успеха поисковика, его популярности у пользователей), а с другой, объясняется желанием исключить искусственную накрутку рейтинга сайта, разными ухищрениями продвинуть его в первые строки результатов поиска. Сделать сайт более весомым для поисковой системы можно, например, если добавить в список ключевых слов (<META name="keywords" content="...">) популярные слова, не относящиеся реально к теме сайта. Можно эти слова написать и в теле самой страницы так, чтобы они были видны только пауку поисковой системы и не видны пользователю (использовать цвет шрифта, совпадающий с цветом фона). Владельцы поисковых систем стараются учитывать ухищрения недобросовестных сайтодержателей, внося поправки в алгоритмы ранжирования. Ведь успех индекса напрямую зависит от релевантности результатов поиска, то есть от того, насколько представленные результаты будут соответствовать ожиданиям пользователя. Например, легко обнаружить в коде страницы символы, которые выводятся на экран цветом фона. Несложно проверить, встречаются ли ключевые слова, заданные в теге META реально в содержании самой страницы. Чтобы сделать сайт более весомым для поисковой системы нужно при его написании учитывать факторы, влияющие на вес ссылки для важных слов на его страницах:
Отказ от индексацииВася. После знакомства с принципами работы индексов, мне почему-то представился мультик “Козленок, который считал до десяти” на новый лад: страшный паук поисковой системы проиндексировал без всякого разрешения козлёнка-сайт!
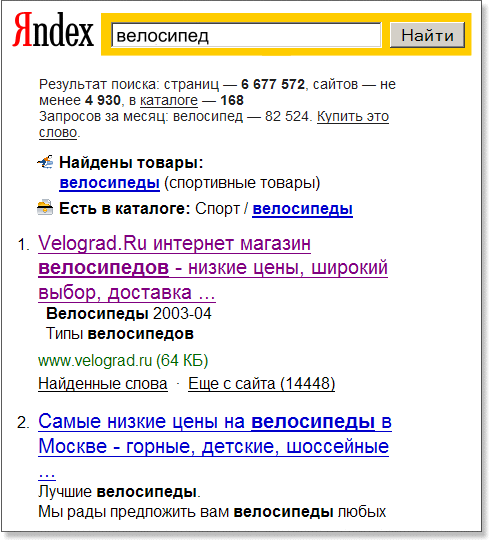
Петя. По “правилам чести” поисковых систем пауки обязаны посмотреть, не лежит ли в корневом каталоге сайта файл robots.txt. В этот файл владельцы могут помещать запреты на индексацию сайта или отдельных его страниц. Запрет (или разрешение) может относиться ко всем или только к некоторым поисковикам. Вот как выглядит robots.txt, запрещающий индексировать сайт всем поисковым системам: # Запрет на индексацию всего сайта любым пауком User-agent: * Disallow: / Вася. Вероятно, паукам редко приходится читать запреты: козлята сами мечтают о том, чтобы их поскорее проиндексировали! Петя. Да, конечно! Кроме специальных сайтов, предназначенных только для узкой компании. Вася. Я немного устал от теории. Может быть, перейдём к практике поиска? Её стратегии и тактике? Петя. Согласен. Давай сначала рассмотрим простой поиск, затем расширенный и, наконец, познакомимся с нюансами языка запросов. Простой поиск. Результаты поискаВася. Я подумываю о покупке хорошего велосипеда. Надо бы почитать в Интернете информацию по этой теме. Чтобы не ошибиться с выбором в магазине. Петя. Весь Интернет перед тобой! Вася. Набираю в строке Яндекса слово “велосипед” и нажимаю кнопку Найти:
Петя. Запрос неудачный: Яндекс обнаружил 6 677 572 страниц с этим словом, и на первое место поместил коммерческие предложения, которые тебя сейчас интересуют не в первую очередь. Вася. То есть релевантность он рассчитал неправильно! Мне хочется прочитать советы по выбору велосипеда. Петя. А что Яндекс мог сделать с одним словом “велосипед”? Как он мог “догадаться”, что именно тебе нужно? На первое место он поместил сайт солидного Интернет-магазина, продающего велосипеды! Нужно стараться использовать многословный образец поиска, более точно соответствующий информационным потребностям — результат будет лучше! Но давай, на примере этого запроса, посмотрим, как Яндекс оформляет результаты поиска. Прежде всего, Яндекс информирует, сколько страниц и сайтов он нашёл по предложенному запросу. Дополнительно сообщает, сколько сайтов по теме запроса нашёл в своём собственном каталоге. Слово каталог оформлено как ссылка, и на ней можно щелкнуть мышкой:
Вася. А что за странное предложение-ссылка “Купить это слово”? Я собираюсь купить велосипед, а не слово! Петя. Как ты думаешь, за счёт чего живут компании, содержащие поисковые системы, ведь свои услуги пользователям они предлагают бесплатно? Вася. Ну, не знаю… Возможно их финансирует государство? Петя. Нет, Вася. Их финансируют фирмы, которые размещают на страницах с результатами поиска свою рекламу! Предложение “купить слово” адресовано как раз к таким компаниям. Когда слово “покупается”, реклама компании размещается на тех страницах, которые Яндекс показывает в ответ на запросы с этим словом, то есть реклама приобретает особую ценность, становится адресной. Вот посмотри, в колонке справа от результатов Яндекс приводит такие рекламные сообщения:
В следующем информационном блоке, непосредственно перед списком результатов, Яндекс приводит ссылки на результаты “параллельных” поисков по другим своим службам, в данном случае по службам Маркет и Каталог:
Вася. Я знаю, что Яндекс — мощный индекс Рунета и достаточно объёмный каталог. Знаю, что Яндекс является провайдером электронной почты, предоставляет место под сайты и даже предлагает завести электронные кошельки (Яндекс-деньги). Какие ещё услуги есть в арсенале этого сетевого монстра? Петя. Яндекс типичный пример портала. Так называют универсальные сайты, предлагающие пользователю широкий спектр услуг. Среди служб Яндекса: поиск картинок и музыки, новости, афиша, телепрограмма, погода, набор словарей, географические карты. Посмотри на поисковую форму Яндекса:
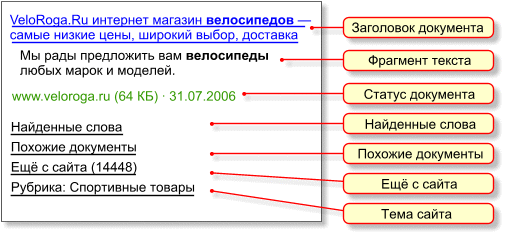
По умолчанию поиск выполняется Везде, но можно ограничить его какой-то конкретной службой из списка-меню: Новости, Маркет, Адреса, Словари, Блоги, Картинки. Полный набор услуг открывается на странице по ссылке Все службы. Вася. Яндекс — молодец! Заботится о пользователях. Поясни, пожалуйста, что означают отдельные поля записи, информирующие о найденном документе. Петя. В этом сообщении можно выделить семь информационных полей:
Вот что они означают:
Я привёл эти пояснения из справочной системы Яндекса, вход в которую расположен над формой для ввода запроса:
Копию справочных страниц Яндекса можно посмотреть без подключения к Интернету здесь: Обрати внимание на ссылку Настроить поиск рядом с помощью. Она позволяет управлять видом результатов поиска. Вася. Продолжу свои велосипедные изыскания. Запишу для Яндекса такой запрос:
Число найденных страниц уменьшилось до 99 613, хотя и остаётся очень большим! Петя. Теперь можно поискать в найденном, поставив соответствующую галочку и задав, например, слово советы:
Вася. Теперь Яндекс нашёл в три раза меньше документов (33 705), а самой первой показал страницу с интересным заголовком “Выбор велосипеда”! Петя. Вот несколько полезных советов для успешного поиска в индексе.
Расширенный поискРасширенный или сложный поиск — это поиск ключевой фразы при дополнительных условиях. Например, в Яндексе из режима простого поиска в расширенный ведёт соответствующая ссылка рядом со строкой ввода запроса:
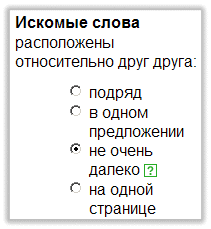
На странице расширенного поиска строка ввода дополняется формой с набором разного рода интерфейсных элементов (флажки, радиокнопки, меню, поля ввода), позволяющие задать условия поиска. Рассмотрим форму для ввода условий на примере Яндекса. Условия на слова из фразы поискаМожно задать условие на расположение слов по отношению друг к другу:
Возможно одно из следующих условий:
Можно задать место расположения слов на странице:
Возможно одно из следующих условий:
Яндекс учитывает морфологию слов запроса и ищет все их формы (идти, идёт, шёл, шла и т. д.). Но можно потребовать искать слова буквально так, как они заданы:
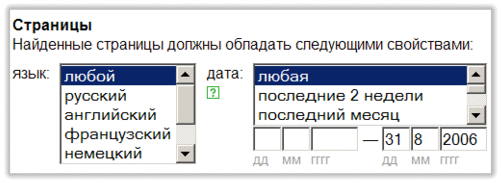
Условия на найденные документыМожно задать условия, которым должны удовлетворять документы в списке результатов поиска:
Язык запросовРасширенный поиск помогает сократить список результатов и повысить его релевантность. Однако более гибким инструментом, позволяющим выполнить “ювелирные” настройки алгоритма поиска, а значит, существенно повысить его эффективность, является язык запросов. Каждая поисковая система имеет собственный язык запросов, порой разительно отличающийся от языка коллег-поисковиков. Рассмотрим самые “ходовые” конструкции языка запросов Яндекса. Более подробная информация содержится на справочных страницах поисковой системы. Копию справочника Яндекса можно посмотреть без подключения к Интернету здесь: Поиск буквальной фразыЭлементы языка запросов: кавычки ("") и знак восклицания (!). Если фраза должна быть найдена буквально в том виде, в котором она указана в запросе, её нужно взять в кавычки.
Кавычки удобны для поиска цитат. Например, по запросу "прошу нажать эсли не аткрывают" будет найдена страница с этим объявлением Совы из повести А. Милна “Винни-Пух и все-все-все”. Для поиска точной формы отдельного слова, его также можно взять в кавычки или поставить перед ним (без пробела) восклицательный знак.
Например, по запросу !хвост отваливается будут найдены документы, содержащие словоформу “хвост” (а не “хвосты”, “хвосту” и т. п.). В результатах поиска окажутся документы с фрагментами:
А вот такие выражения будут проигнорированы:
Обязательное включение и исключение отдельного словаЭлементы языка запросов: знак плюс (+) и знак минус (-). Поисковые машины могут игнорировать стоп-слова (местоимения, предлоги, частицы) или выдавать страницы, на которых некоторые слова из фразы поиска отсутствуют. Если присутствие слова необходимо, в запросе для Яндекса перед ним без пробела нужно поставить знак +. Вот что написано по этому поводу в справочном разделе Яндекса: Чтобы отобрать документы, где определенное слово присутствует обязательно (некоторые слова запроса не учитываются Яндексом), поставьте перед ним плюс (без пробела). Поэтому, если вас интересует цитата из “Гамлета”, вы можете задать запрос +быть +или +не быть. Например, запрос объявления о продаже велосипедов выдаст много страниц с разнообразными объявлениями. А запрос объявления о продаже +велосипедов покажет объявления о продаже именно велосипедов. Для исключения страниц, содержащих определённые слова, нужно использовать знак -. Из справочного раздела Яндекса: Чтобы исключить документы, в которых встречается определенное слово, поставьте перед этим словом знак минус (без пробела). Например, если вам нужно описание Парижа, а не предложения многочисленных турагентств, задайте запрос: путеводитель по Парижу
По запросу:
+гимнастика
+лечебная
По запросу:
!чебурашка
Обязательное включение нескольких словЭлементы языка запросов: знак & (уровень предложения) и знаки && (уровень документа). Если нужен документ, в котором обязательно присутствуют несколько ключевых слов, в запросе они соединяются знаком & (слова обязаны быть в одном предложении) или знаком && (слова обязаны быть в одном документе). Управляющие знаки оделяются от слов пробелами с обеих сторон. Таким образом, по запросу: Шарик & удивление & обморок Будет найден (среди прочих) документ, в котором присутствует предложение: Шарик даже в обморок упал от удивления. По запросу: заметка && Федор && примета && сообщение Будет найден (среди прочих) документ с таким фрагментом: — Надо заметку в газете напечатать, что пропал мальчик. Зовут дядя Федор. И все его приметы описать. Если кто увидит, пусть нам сообщит. Вариант исключения объекта (уровень предложения и документа)Элементы языка запросов: знак ~ (уровень предложения) и знаки ~~ (уровень документа). Эти знаки (они обрамляются пробелами с обеих сторон) можно использовать в запросах следующего формата: что искать ~ что исключить (уровень предложения) что искать ~~ что исключить (уровень документа) Пример из справочника Яндекса: Если вы ищите информацию о г-же Кузькиной, то более информативные результаты даст запрос Кузькина ~ мать, который ищет страницы со словом Кузькина, исключая страницы, где в одном предложении с ним есть слово мать. Пример из справочника Яндекса: Если вы ищете информацию о Задорнове (но не министре), можете задать запрос Задорнов ~~ министр. Будут найдены все страницы, где есть слово Задорнов, и нет слова министр. Задание вариантовЭлемент языка запросов: знак |. В простом запросе (без использования элементов языка) Яндекс считает наиболее релевантными документы, в которых встречаются все слова заданной ключевой фразы. Но часто одни и те же вещи авторы называют по-разному. Например, педант пишет: “персональный компьютер”, а минималист: “ПК”. Поиск персонального компьютера не покажет статьи минималиста, а поиск ПК — статьи педанта. Знак | можно использовать в качестве логической операции ИЛИ для разделения возможных вариантов. Так по запросу: "персональный компьютер" | ПК Будут найдены статьи и педанта, и минималиста. Комбинированные запросыЭлементы языка запросов: ( и ). Разные конструкции языка можно применять в одном запросе, дополнительно используя круглые скобки для группировки. Например, по запросу:
устройство
&
("персонального компьютера"
|
ПК)
будут найдены документы с описанием устройства персонального компьютера, в которых речь не идёт о продаже. Пример из справочника Яндекса: Если вы ищете описание мумие, но не хотите наталкиваться на прайсы интернет-магазинов, можете задать такой запрос: Популярные индексыНиже приводится краткие описания нескольких популярных индексов Интернета. ЯндексАдрес в Интернете: www.yandex.ru Вид главной страницы:
Адрес “облегчённого” варианта: www.ya.ru Число проиндексированных страниц на 4 сентября 2006 года — 1 118 458 841. На время написания книги — самый популярный индекс Рунета. Яндекс — большой портал Рунета. В состав этой системы входят: каталог, индекс, специализированные поисковые службы (поиск товара, картинок, музыки, определений, карт, адресов…) Яндекс предлагает провайдерские услуги (почта, место под сайт), интернет-кошельки (Яндекс-деньги), справочный материал разного характера (новости, погода, афиша, телепрограмма…) Описание всех служб Яндекса можно найти на странице: www.yandex.ru/all_services.html История Яндекса подробна описана на: company.yandex.ru/history Эти страницы можно посмотреть без подключения к Интернету здесь: Адрес в Интернете (вариант для России): www.google.ru Вид главной страницы:
Более 8 миллиардов проиндексированных страниц. На время написания книги — один из самых популярных (если не самый популярный) индексов Интернета. И это, несмотря на то, что компания Google Inc. очень молода: она была основана в сентябре 1998 года Лэрри Пэйджем (американец) и Сергеем Брином (уроженец Москвы). Сегодня Google абсолютный мировой лидер по объему проиндексированных документов, быстроте обработки запроса и корректности ранжирования результатов поиска. Google — это не только индекс. В арсенале системы: собственный каталог, поиск картинок, почтовая служба, списки рассылки (группы Google), географические интерактивные карты. Группы Google: groups.google.com Почтовая служба Google (завести свой ящик можно только по приглашению другого пользователя): mail.google.com Интерактивные карты Google: maps.google.com Следующие элементы языка запросов Google работают так же, как в Яндексе:
Запросы нечувствительны к регистру символов. Круглые скобки в запросе использовать можно, но на них Google (увы!) не обращает внимания. Применение спецсимвола ~ дает Google команду искать не только указанное слово, но и его синонимы (которые Google для каждого слова подбирает самостоятельно). Интересен спецсимвол *, который задаёт подстановку в запрос одного любого слова. Применяя знак несколько раз можно задавать точные промежутки между частями поисковой фразы. Так для запроса "дерево * * * птичка" подходит фраза: Встало солнышко, лучи позолотили верхушки деревьев, захрюкали свиньи, запели птички. но не подходит фраза Среди ветвей деревьев порхали птички. Ещё одна интересная возможность: если перед словом (или фразой) в запросе записать define:, Google попытается найти страницы с определениями этого слова или фразы. Так по запросу define:язык программирования будет найдена страница, содержащая определение: Язык программирования — формальная знаковая система, предназначенная для описания алгоритмов в форме, которая удобна для исполнителя (например, компьютера). История Google описана здесь: РамблерАдрес в Интернете: www.rambler.ru Вид главной страницы:
“Минимальная” страница: www.r0.ru Число проиндексированных страниц на 4 сентября 2006 года — 1 368 956. Не так давно Рамблер был лучшим поисковым порталом Рунета. Сейчас индекс Рамблера существенно уступает индексу Яндекса, но Рамблер по-прежнему остаётся лучшим рейтингом Рунета (на 4 сентября 2006 года в рейтинге Рамблера участвуют 148 498 сайтов, распределённые по 48 тематическим категориям). По числу сервисов портал Рамблер не уступает, а даже превосходит портал Яндекс: индекс, рейтинг сайтов, рейтинг магазинов, почта, покупки, словари, географические карты, новости, спорт, погода, юридическая консультация, рассылки… Все сервисы Рамблера: www.rambler.ru/all.shtml Справочная служба Рамблера: help.rambler.ru Эти страницы можно посмотреть без подключения к Интернету здесь: Язык запросов Рамблера поддерживает круглые скобки, кавычки и знак | в тех смыслах, что и Яндекс:
Аналогом указания Яндекса ~~ для Рамблера является ключевое слово NOT: что искать NOT что исключить (уровень документа) Знак ~ Рамблер использует в качествен логической операции И (обязательное включение), но указание относится к уровню документа, а не уровню предложения, как в Яндексе. Другие индексы РунетаАпорт! Адрес в Интернете: www.aport.ru Вид главной страницы:
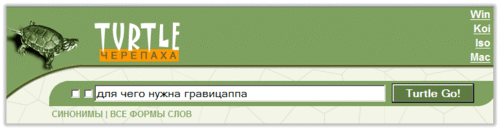
“Минимальная” страница: au.ru Turtle Адрес в Интернете: www.turtle.ru Вид главной страницы:
“Минимальная” страница: www.turtilla.ru
|
|||||||||||||||||||||||||||||
|
|
Выход из читального зала |
 Для облегчения поиска информации в книгах, особенно научных, часто
используют индекс. Иногда индекс называют
предметным указателем, алфавитным указателем или
просто указателем.
В индексе перечислены по алфавиту все основные понятия, которые есть
в книге, и указано, на каких страницах они встречаются.
Для облегчения поиска информации в книгах, особенно научных, часто
используют индекс. Иногда индекс называют
предметным указателем, алфавитным указателем или
просто указателем.
В индексе перечислены по алфавиту все основные понятия, которые есть
в книге, и указано, на каких страницах они встречаются.